Both private and public sector research organizations must adopt data management strategies that keep up with the advent of big data if we hope to effectively and accurately conduct research. CIMMYT and many other donor-dependent research organizations operate in fund declining environments, and need to make the most of available resources. Data management strategies based on the data lake concept are essential for improved research analysis and greater impact.
We create 2.5 quintillion bytes of data daily–so much that 90% of the data in the world today has been created in the last two years alone. This data comes from everywhere: sensors used to gather climate information, drones taking images of breeding trials, posts on social media sites, cell phone GPS signals, and more, along with traditional data sources such as surveys and field trial records. This data is big data, data characterized by volume, velocity, and variety.
Twentieth century data management strategies focused on ensuring data was made available in standard formats and structures in databases and/or data warehouses–a combination of many different databases across an entire enterprise. The major drawback of the data warehouse concept is the perception that it is too much trouble to put the data into the storage system with too little direct benefit, acting as a disincentive to corporate-level data repositories. The result is that within many organizations, including CIMMYT, not all data is accessible.
Today’s technology and processing tools, such as cloud computing and open-source software (for example, R and Hadoop), have enabled us to harness big data to answer questions that were previously out of reach. However, with this opportunity comes the challenge of developing alternatives to traditional database systems–big data is too big, too fast, or doesn’t fit the old structures.
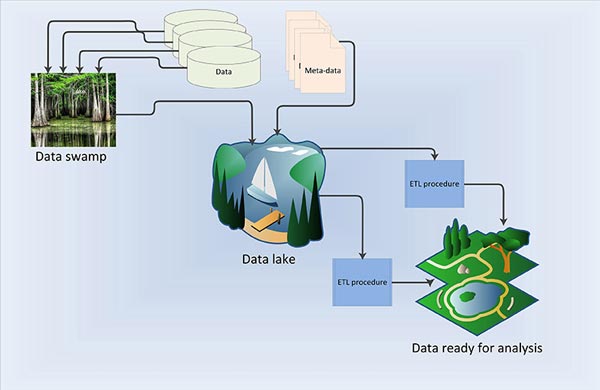
One alternative storage and retrieval system that can handle big data is the data lake. A data lake is a store-everything approach to big data, and a massive, easily accessible, centralized repository of large volumes of structured and unstructured data.
Advocates of the data lake concept believe any and all data can be captured and stored in a data lake. It allows for more questions and better answers thanks to new IT technologies and ensures flexibility and agility.However, without metadata–data that describes the data we are collecting–and a mechanism to maintain it, data lakes can become data swamps where data is murky, unnavigable, has unknown origins, and is ultimately unreliable. Every subsequent use of data means scientists and researchers start from scratch. Metadata also allows extraction, transformation, and loading (ETL) processes to be developed that retrieve data from operational systems and process it for further analysis.
Metadata and well-defined ETL procedures are essential for a successful data lake. A data lake strategy with metadata and ETL procedures as its cornerstone is essential to maximize data use, re-use and to conduct accurate and impactful analyses.
 Capacity development
Capacity development 
